-
Product

SmartAsk
Ask in one sentence. Get answers instantly

Sage AI
AI Ops Agent Workbench

AI Observability
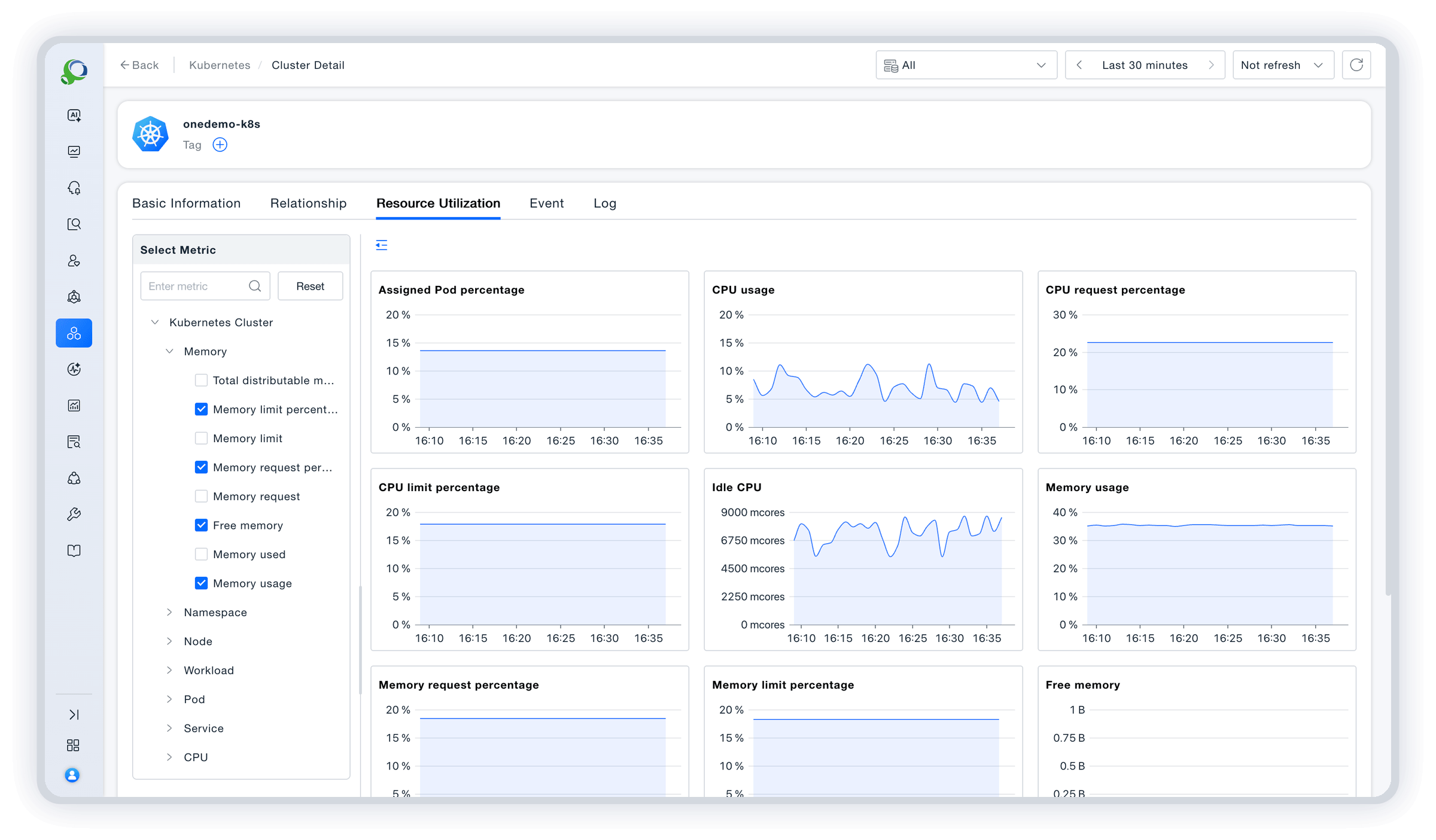
Full-lifecycle AI observability

Dashboard
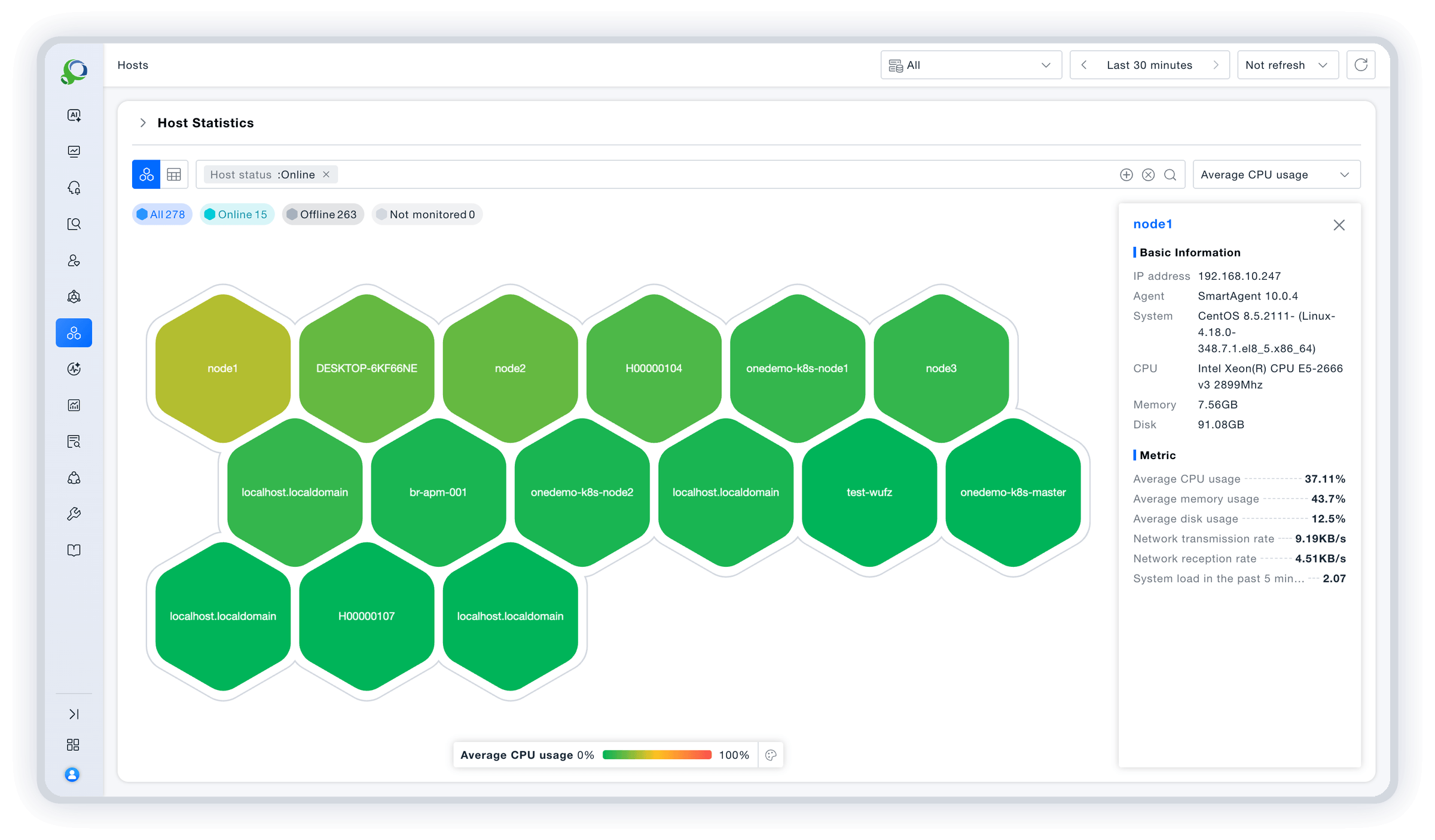
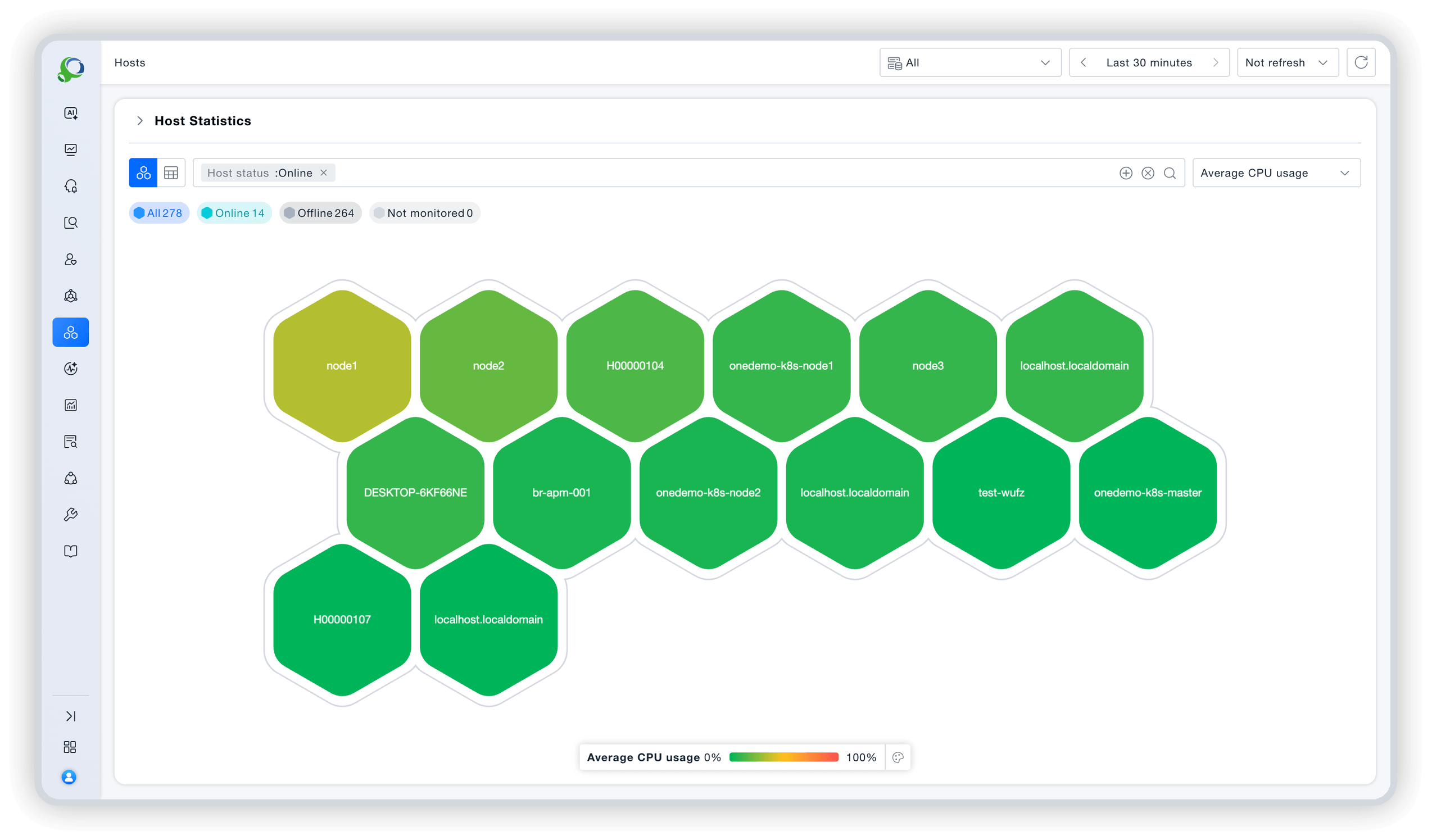
Unified visualization, one-screen insight

Monitors
Precise alerts. Zero noise. Fast response
-
Customer Stories
- Bank Kunlun Bank Bank of Zhengzhou China Everbright Bank China Construction Bank Huaxia Bank Fubon Bank (China)
- Securities Sinolink Securities Shanghai Securities Guotai Haitong Securities China Merchants Securities Orient Securities China Securities Hongta Securities
- Insurance New China Life Insurance Taikang Insurance
- Internet Yaoshi Bang The Economic Observer Media Tencent Video JD Zhilian Cloud Zhengbao Education 51talk DHgate
- Energy State Grid Jibei Electric Power Company State Grid Big Data Center Haopeng Technology Yalong River Hydropower China Datang Sinopec CNOOC
- Manufacturing China Railway Information Technology WangLaoJi Andi Supply Chain C&S Paper Blue Moon China Tower Anta Sports Mengniu Group Moutai
- Public Affairs SarawakInformation Systems Sdn Bhd China Railway
- Telecommunication Huawei Unicom Wo Music
- Resource Center
- Pricing
- About Us
- Blog
- Contact Us










 Core Capabilities
Core Capabilities