















ZooKeeper is an open-source distributed coordination system widely used for metadata coordination in distributed systems. However, in our production environment, several limitations became increasingly critical and began to impact business stability and user experience.
To address these challenges, Bonree ultimately chose to replace ZooKeeper with ClickHouse-Keeper, improving write performance, reducing maintenance overhead, and simplifying cluster management. To achieve a smooth migration, we also had to carefully consider automated upgrades, authentication compatibility, data migration, and data validation.
ZooKeeper vs ClickHouse-Keeper in Bonree
1. Performance and scalability limitations of ZooKeeper
As data volume and data types continued to grow, ZooKeeper became a major bottleneck for ClickHouse clusters, especially in real-time scenarios such as alert ingestion requiring second-level latency.
Key issues observed:
1.1 Limited scalability
In our self-built cloud environment, with Keeper deployed on 4C8G resources and a 3-node ZooKeeper cluster:
One cluster supports up to 5 shards (each shard: 16C32G, double replication)
Each shard generates approximately 20,000 parts
Total parts across 5 shards reach around 100,000
As data and table numbers increase, cluster expansion becomes inevitable. For every additional 5 shards, a new ZooKeeper cluster must be deployed, leading to significant operational overhead.
1.2 Performance bottlenecks
Initial state: 1TB data, ~12,000 parts → insertion latency in milliseconds
As parts grow to ~20,000 → insertion latency increases to tens of seconds
This leads to delayed ingestion, stale query results, and degraded user experience.
1.3 High resource consumption
ZooKeeper consumes significantly more resources compared to ClickHouse-Keeper:
Memory usage: ~4.5× higher
I/O usage: ~8× higher
1.4 Stability issues
ZooKeeper (Java-based) suffers from:
Frequent Full GC under improper memory tuning
Service interruptions affecting ClickHouse performance
zxid overflow issues in extreme cases
Additionally, replica synchronization depends heavily on ZooKeeper. When ZooKeeper performance degrades, background threads may become overloaded, causing replication delays and backpressure.
In our production environment, replica delay queues exceeded 10,000+ pending parts, severely affecting query freshness and correctness.
2. Why ClickHouse-Keeper
Given the above limitations and the write-heavy, analytics-oriented workload, Bonree selected ClickHouse-Keeper as a replacement.
2.1 Compatibility
ClickHouse-Keeper is fully compatible with ZooKeeper client protocols:
No client-side modification required
Standard ZooKeeper clients can connect directly
Seamless integration with ClickHouse ecosystem
2.2 Data migration
We used the clickhouse-keeper-converter tool to migrate ZooKeeper snapshots:
Converts ZooKeeper snapshots into ClickHouse-Keeper format
Supports millions of nodes in minutes
Reduces service downtime significantly
2.3 Improved stability
ClickHouse-Keeper is written in C++:
Eliminates Java GC-related issues
Provides more stable runtime behavior
Better controllability via runtime tuning
2.4 Better performance and resource efficiency
Metadata is stored in a more compact format
Lower CPU, memory, and disk I/O usage
Significantly higher throughput under the same hardware conditions
Evolution of Bonree’s Architecture
1. Original ZooKeeper-based architecture
As business complexity increased, Bonree introduced:
Multiple ClickHouse clusters for different SLA levels
Physical resource isolation for critical vs general workloads
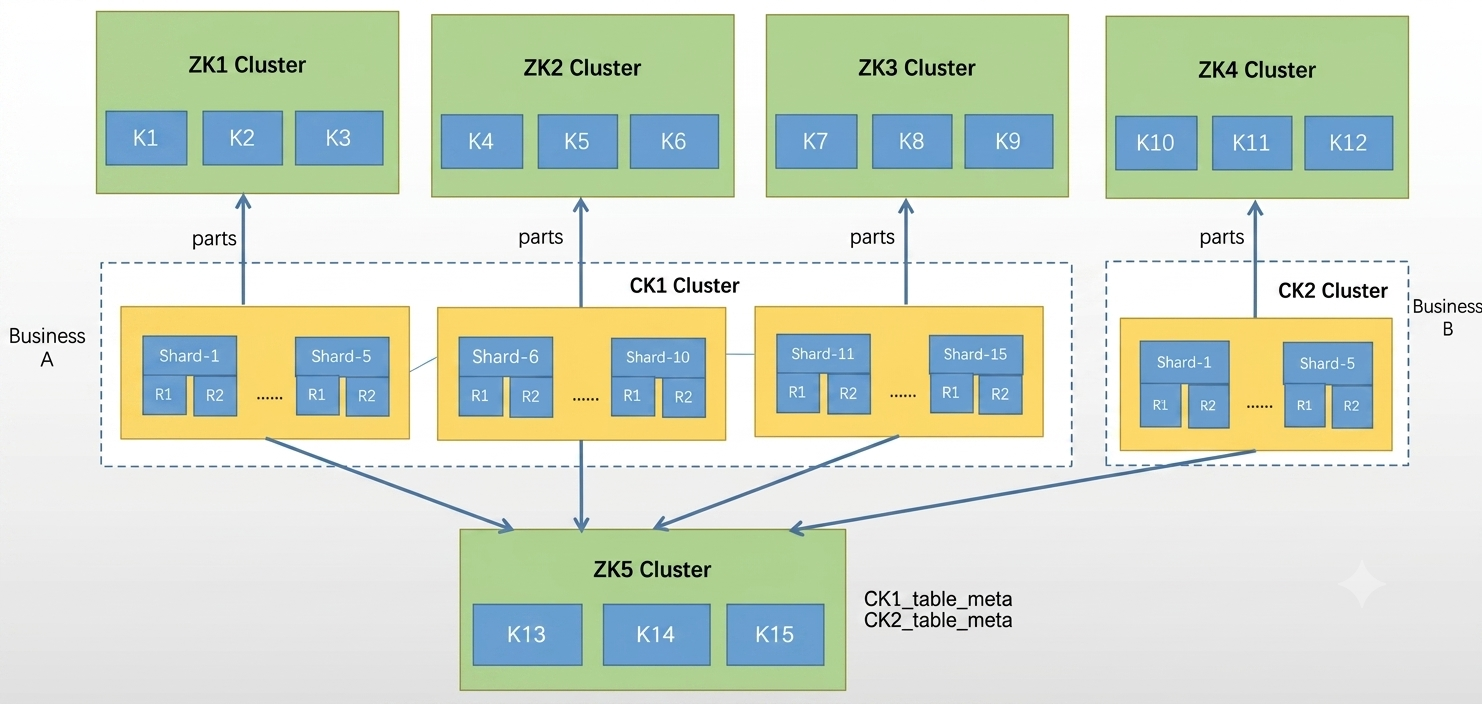
Initially, ZooKeeper was used in a multi-cluster architecture:
5 ZooKeeper clusters for shard management and metadata separation
Each cluster managing ~5 shards
One shared cluster for metadata storage
However, this led to:
15 ZooKeeper nodes in total
High operational complexity
Increasing performance and stability risks
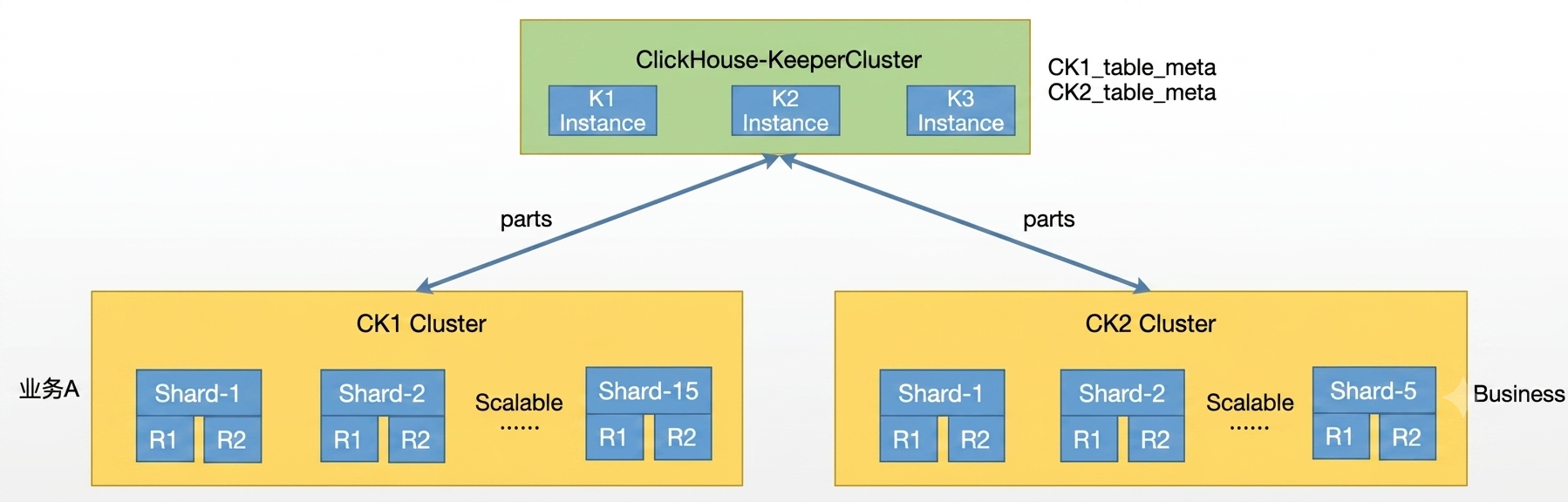
2. ClickHouse-Keeper-based architecture
After adopting ClickHouse-Keeper:
ZooKeeper clusters were consolidated
A single ClickHouse-Keeper cluster can support 15+ shards
Operational complexity significantly reduced
Improved ingestion performance and replication stability
3. Pre-migration preparation
Even after stopping data ingestion, ClickHouse background tasks (e.g., merges) continue modifying ZooKeeper metadata.
To ensure consistency:
We used
SYSTEM STOP MERGESPaused all background metadata modifications
Ensured ZooKeeper and ClickHouse-Keeper snapshots remained consistent
This enabled accurate pre- and post-migration validation with minimal downtime (within ~30 minutes).
4. Automated migration (ZooKeeper → ClickHouse-Keeper)
To eliminate manual errors, Bonree built an Ansible-based automation framework.
Migration steps:
Stop ClickHouse DDL operations
Stop data ingestion processes
Record baseline metrics
Restart ZooKeeper clusters to capture latest snapshots
Convert snapshots to ClickHouse-Keeper format
Load snapshots into ClickHouse-Keeper
Perform sampling-based consistency checks
Switch ClickHouse metadata configuration
Validate metrics and restart background tasks
Core automation logic:
Stop ClickHouse managers
Stop data consumers
Stop merge operations
Collect latest ZooKeeper snapshots
Convert snapshot format
Deploy ClickHouse-Keeper cluster
Validate data consistency
This reduced migration time from 2–3 hours to minutes, significantly improving operational efficiency.
Key Challenges in Production
1. Multi-ZooKeeper to single ClickHouse-Keeper migration
The official tool only supports one-to-one migration, but Bonree required consolidation of multiple ZooKeeper clusters into a single ClickHouse-Keeper cluster.
Solution:
Sampling-based validation before and after migration
Source code modification of converter tool
Support for merging multiple snapshots into one cluster
2. Authentication and encryption compatibility
ZooKeeper environments varied across customers:
Fully encrypted clusters
Non-encrypted clusters
Mixed configurations
Handling strategies:
Case 1: Fully consistent configuration
Same ACL rules across clusters
Direct migration without modification
Case 2: No encryption
Direct migration supported
Case 3: Mixed configurations
Remove ACL enforcement
Standardize ClickHouse-Keeper configuration
Steps included:
Adding temporary super admin
Resetting ACL rules
Removing authentication after migration if needed
3. Fast validation of large-scale metadata
ZooKeeper does not provide efficient full-path enumeration.
Optimization approach:
Export all paths into a
pathlogfile during conversionReplace expensive ZooKeeper queries with file-based sampling
Reduce validation time from ~9 hours to seconds
4. Consistency validation strategy
Compare sampled paths across multiple ZooKeeper clusters
Classify paths into:
Unique paths (must exist in only one cluster)
Shared paths (must match across clusters)
This ensures correctness across merged environments.
5. ClickHouse-Keeper tuning
Key optimizations:
max_requests_batch_size = 10000force_sync = falsecompress_logs = truecompress_snapshots_with_zstd_format = true
Results
After replacing ZooKeeper with ClickHouse-Keeper, Bonree achieved significant improvements:
CPU and memory usage reduced by 75%+
I/O overhead reduced by ~8×
Write performance improved by ~8×
Near-zero failure rate in production
Significantly simplified cluster operations
Conclusion
By migrating from ZooKeeper to ClickHouse-Keeper, Bonree successfully eliminated a major metadata bottleneck in large-scale ClickHouse deployments.
The new architecture:
Improves ingestion performance
Reduces operational complexity
Enhances system stability
Lowers infrastructure cost
ClickHouse-Keeper proved to be not only a replacement for ZooKeeper, but a significantly more efficient coordination layer for large-scale ClickHouse-based observability systems.